ios
加速器 服务器位于 12 个国家,包括美国、英国、俄罗斯、荷兰、德国、卢森堡、乌克兰、爱沙尼亚、波兰、加拿大、法国和意大利。
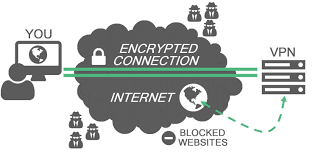
一款免费提供手机网游加速服务的APP,解决了无法登录、频繁死机、高延迟、掉线等问题,提供丰富的一手日韩手机游戏资讯。不能一直吃鸡怎么办?网络加速器祝你吃鸡好!游戏加速哪些强软件可以通过底层技术清理手机,加速网络优化,打通手机二线。这是一个完全无限制的免费虚拟专用网。
服务器数量众多,高速带宽,选择使用VPN的应用(需要Android 5。通过垃圾清理和内存释放,一键解决手机卡顿问题。该服务支持 Open加速器、PPTP、L2TP 和 SSTP 协议。一款非常实用的手机网游加速器软件!以专业的手游加速能力深受玩家们的好评,操作简单,一键加速,效果显著,快速解决掉线,跳ping等问题,让您享受更流畅的游戏体验。
波音客机又出事!空中起火 发动机不断喷出火焰